
Discovery Sprint • Enterprise RAG • Singapore
Enterprise RAG Assistant Discovery Sprint (Singapore)
In 2 weeks, we define the highest-ROI use case, validate data readiness, and produce an evaluation + security plan for a permission-aware RAG search/chat pilot your team can actually ship.
Want the deeper technical approach? See our RAG stack and delivery approach.
Who it’s for
When “the answer exists somewhere” is costing time and trust
Built for teams adopting enterprise AI search/chat where correctness, permissions, and traceability matter.
Scattered internal knowledge
Ops, HR, IT, Finance, and Support teams juggling wikis, drives, tickets, and threads.
Governed / regulated environments
You need permission-aware retrieval, audit logs, and a clear deployment boundary (cloud/VPC, SSO/RBAC).
What you get in 2 weeks
Specific deliverables (so you can greenlight a pilot with confidence)
This is a planning sprint for enterprise RAG implementation—use-case clarity + data access + evaluation + security + pilot scope.
Deliverables
- Use-case shortlist + recommendation (highest ROI + lowest risk)
- Source + access review (systems, owners, permission model, constraints)
- Success metrics + evaluation plan (offline eval set, acceptance thresholds, UX feedback)
- Pilot scope + timeline (MVP features, milestones, resourcing)
- Deployment & security plan (cloud/VPC, RBAC/SSO, logging, boundaries)
Output format
Written readout
A decision-ready doc your stakeholders can use to approve budget, scope, and deployment approach.
Pilot plan you can execute
Clear next steps: what to build, what to connect, how to measure, and how to deploy safely.
If you already have requirements and want implementation, see Technology.
How it works
Three steps, end-to-end
Workshop → source review → written readout + pilot plan.
Step 1
Stakeholder workshop
Align on users, workflows, risks, and what “good” looks like (accuracy, latency, adoption, governance).
Step 2
Source + access review
Identify candidate sources, permission boundaries, and the connector/ingestion plan (including change tracking).
Step 3
Readout + pilot scope
Deliver the recommended use case, evaluation plan, and deployment/security approach—ready for pilot execution.
Reference architecture
RAG search & chat that’s permission-aware and measurable
Embed your architecture diagram here, then use this checklist to explain what makes an enterprise-ready assistant.
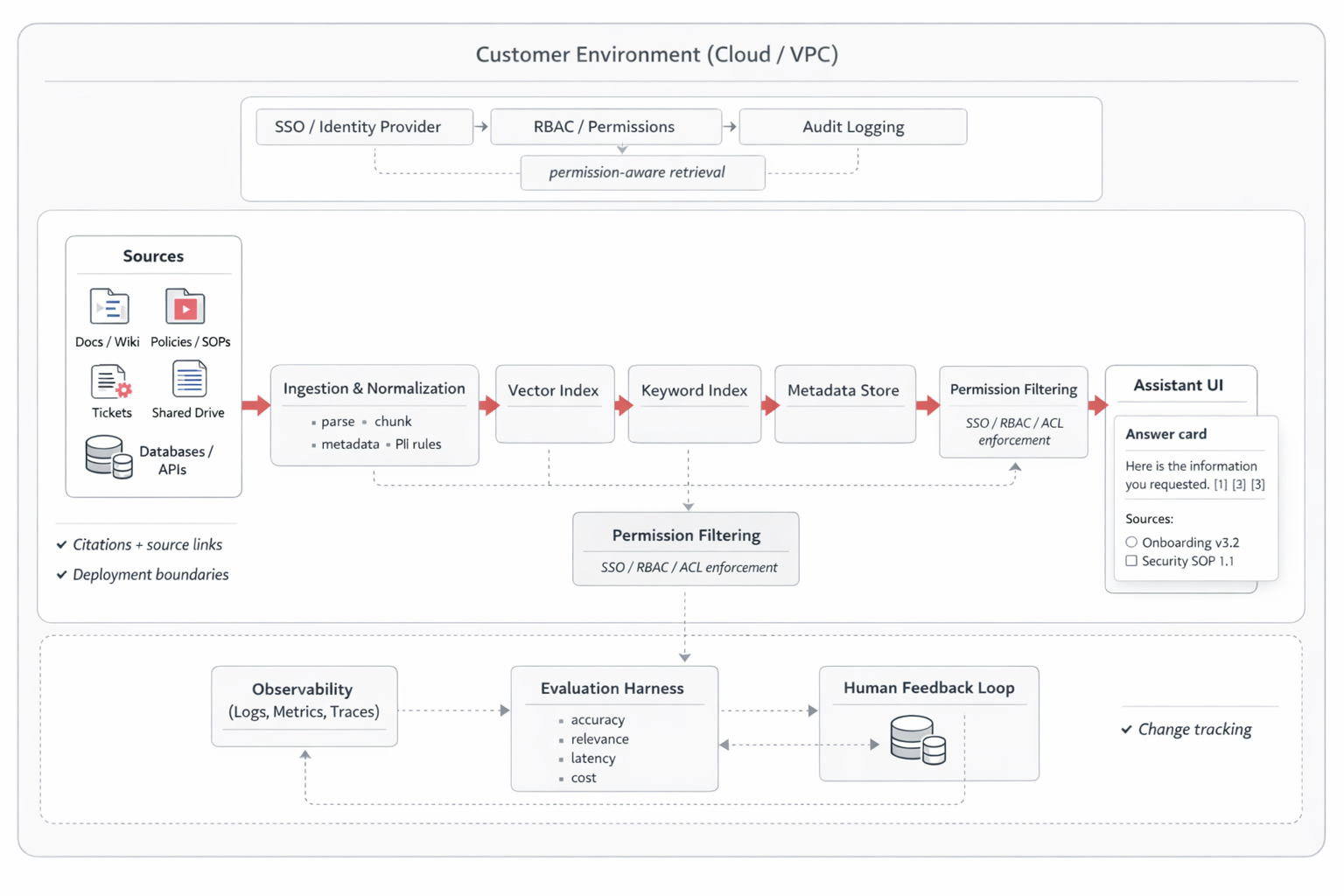
What we design for
- Retrieval + reranking for relevance (hybrid search where needed)
- Permission-aware filtering (SSO/RBAC/ACL enforcement)
- Citations and source links for verification
- Logging + evals (offline test sets + live feedback)
- Monitoring for latency, cost, and quality regressions
- Deployment boundaries (cloud/VPC + data handling constraints)
- Fallback behavior when confidence is low (clarify or “I don’t know”)
- Change tracking so answers stay aligned as docs evolve
For deeper detail on implementation choices, see Technology.
Typical use cases
Common enterprise assistants for RAG pilots
Each card links to a short “learn more” section, plus you can explore our broader library of assistants on the homepage.
Internal knowledge assistant
Find SOPs, policies, and “how we do things” answers with citations.
Learn more →
Support copilot
Draft accurate replies faster, grounded in tickets + help content.
Learn more →
Onboarding & enablement
Speed up ramp time with permission-aware “latest approved” answers.
Learn more →
Compliance Q&A
Policy-aligned answers designed for traceability and auditability.
Learn more →
Internal knowledge assistant
Best when teams lose hours across wikis/drives/tickets. We prioritize citations + permission-aware retrieval from day one.
Support copilot
Best when quality and speed both matter. We scope guardrails, review workflows, and measurable improvements (handle time, FCR).
Onboarding & enablement
Best when “the latest doc” is unclear. We design retrieval patterns for versioning + approvals.
Compliance & governance Q&A
Best for regulated/governed orgs. We build around traceability, access controls, and audit logs.
Browse “Common assistants we ship” on the homepage: see use cases.
FAQs
Enterprise RAG Discovery Sprint FAQs
Common questions buyers ask when starting an AI assistant pilot.
Will it hallucinate?
We design for grounded answering: retrieval + reranking, permission-aware filtering, citations, and fallbacks when confidence is low. We also define evaluation sets and acceptance thresholds before rollout.
Do you support citations?
Yes—citations and source links are a default. We tune chunking and retrieval so citations map cleanly back to the right section of a doc.
How do access controls work (SSO/RBAC)?
We enforce permission-aware retrieval so users only see what they’re allowed to see. SSO/RBAC constraints and audit needs are captured in the sprint deployment/security plan.
What deployment options do you support?
We can deploy to your cloud account/VPC (AWS/Azure/GCP) with defined boundaries, logging, and monitoring. We’ll recommend the safest path during the sprint.
What’s the timeline after the 2-week sprint?
The sprint ends with a pilot plan you can execute immediately. Typical pilots are 2–6 weeks depending on sources, permissions, and UX scope.
What sources can you connect to?
Common sources include SharePoint, Confluence, Google Drive, S3/GCS, databases, ticketing systems, and internal APIs. We confirm feasibility and access during the sprint.
Final step
Ready to turn scattered knowledge into a trusted AI assistant?
Book a short call. You’ll leave with a clear recommendation on the best starting use case, the likely pilot scope, and what it takes to deploy safely.
Singapore-based. Available for on-site workshops when helpful.